前言 找工作第三天了,线上线下面了有不少了 ,其中有部分的问题回答的不是很nice,用这篇文章来记录一下,再去剖析一番
HTML <script> ,<script async> <script defer> 的区别分别是什么
在HTML中类似 async 和 defer,checked 等等 这种叫做 布尔属性 ,布尔属性的存在意味着 true 值,布尔属性的缺失意味着 false 值。
当时不太了解 defer这个属性,现在做个对比
<script>不管是内部代码,还是 src 加载的远程代码,都会阻塞 DOM 的解析<script async> (多个请求加载时顺序不能保证一致)
内部代码:会阻塞 DOM 解析
远程代码:请求时不会阻塞, 执行代码时会阻塞
<script defer> 无论何时都不阻塞代码,触发 DOMContentLoaded 事件前执行
script标签
JS执行顺序
是否阻塞解析 DOM
<script>HTML 中的顺序
阻塞
<script async>网络请求返回顺序
有代码执行阻塞,没代码执行不阻塞
<script defer>在HTML 中的顺序
不阻塞
CSS 哪些属性可以触发BFC ? 当时说了一些没太说清楚
列下几个常用的
浮动元素: float 不为 none
绝对定位元素: position 为 absolute 或 fixed
行内快元素:display 属性为 inline-block
表格单元格为 table-cell 值 (table的默认值)
rem 如何计算 ? 移动端没追问太多,移动端项目少
rem 是一个相对单位
layout-viewport (布局视口) / 设计稿宽度
document.body.clientWidth / 750 * 基数 = Html fontSize
(function ( var a = document .documentElement .clientWidth || document .body .clientWidth ; if (a > 460 ) { a = 460 ; } else { if (a < 320 ) { a = 320 ; } } document .documentElement .style .fontSize = (a / 750 * 100 ) + 'px' ; })();
不过移动端适配都有方案处理好了,postcss-px2rem等
Javascript Javascript实现帧动画 ? 当时一时没反应过来😢,后来才想起,不过这个API用的比较少
window.requestAnimationFrame(callback)
该回调函数执行次数通常是每秒60次,但是在大多数浏览器中进行了优化,运行在后台标签页中或者是 <iframe/> 中会被暂停调用
详细参考 👉🏻 window.requestAnimationFrame - Web API 接口参考 | MDN (mozilla.org)
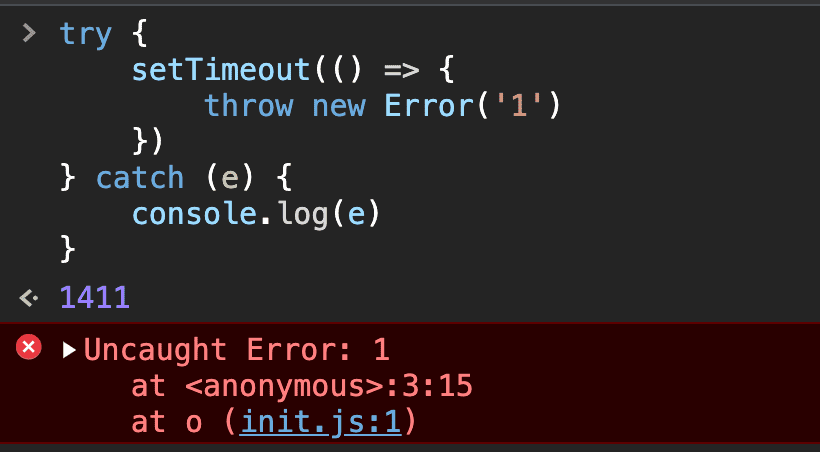
try 中写异步代码报错了,catch 中是否能捕获到? 为什么? 不能,因为JavaScript事件循环机制导致的
try { setTimeout (() => { throw new Error ('1' ) }) } catch (e) { console .log (e) }
在上面这段代码中,并不能捕获到错误,可以复制在浏览器控制台中去试试。
其原因就是在JavaScript的执行过程中,执行到第二行的时候(setTimeout这个位置),会把setTimeout中的回掉函数放入 任务队列,等到同步代码执行完成后,才回去执行队列中的任务,所以在 try 代码块执行完后,程序此时还没有报错,于是就不会走到 catch 里面,所以setTimeout 其实是最后才执行的,所以不会被捕获到,如下图 👎🏻
Promise 这个后面单独写一篇博客,这个问的太多了
generator 的 迭代器中 next方法的参数怎么用? next 的参数会在generator 函数中用作 yield 值返回的结果(只在函数体里有效,不会影响到next.value的值)
使用值调用next。 注意,第一次调用没有记录任何内容,因为生成器最初没有产生任何结果。
function * generator ( while (true ) { var value = yield null ; console .log (value); } } let g = generator ();g.next (1 ); g.next (2 );
解释一下JavaScript的同步异步,宏任务和微任务 ? HTTP http哪些头可以设置强缓存和协商缓存? 强缓存 ( 不会发起请求 )
Cache-Control
Expires (过期时间)
协商缓存 (发起请求校验,如果命中缓存则返回304)
Last-Modified / If-Modified-Since (都是GMT格式的时间字符串,如何客户端和服务端时间不统一,可能会存在问题)
Etag / If-None-Match (值由服务器生成唯一标识,如果文件有变化,这个值也会改变)
Etag 就是为了解决,Last-Modified 可能会存在时间不一致的另一种策略。
优先级: Cache-Control > Expires > Etag > Last-Modified
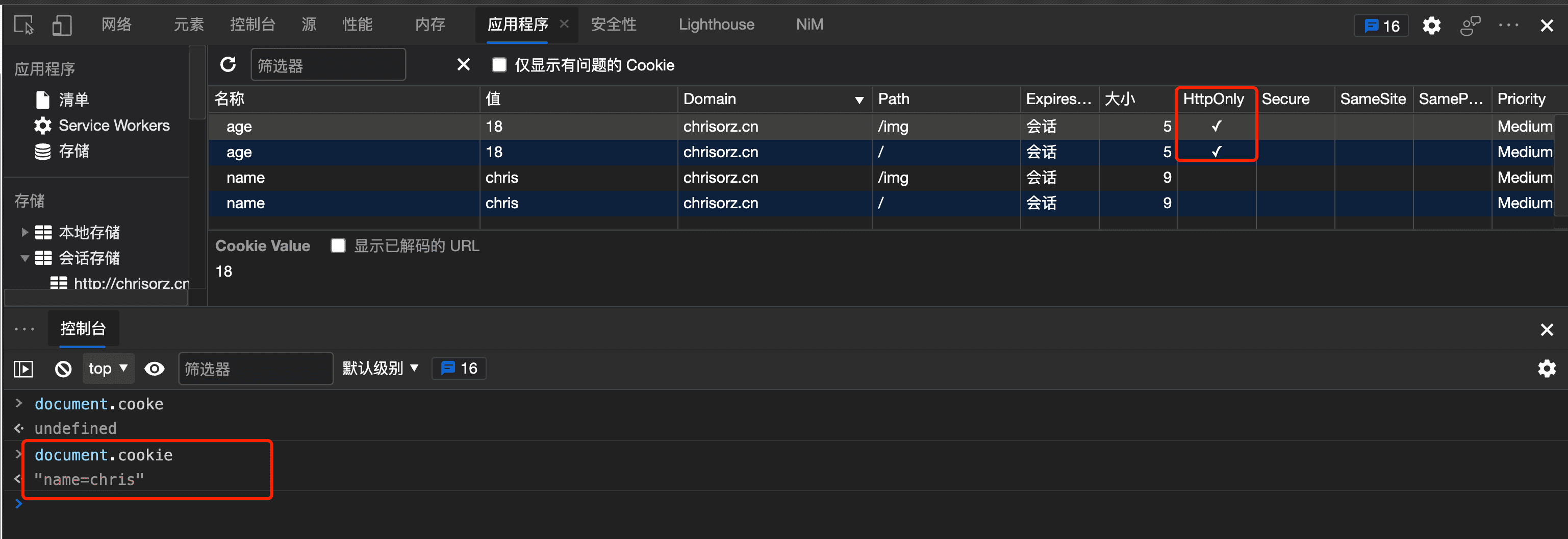
Cookie 中 httpOnly 的作用是什么 ? 预防CSRF (跨站请求伪造)攻击,设置后的cookie字段,则通过JavaScript 访问不到(document.cookie)也就操作不了 从根本上解决问题😂
但是可以通过浏览器调试工具Application 这一栏看到
CORS中预检请求中(Prefilight request)的作用是什么 ? 个人理解:在发送一些不安全的请求之前,浏览器会自动的发送一个options请求,也是就 CORS 预检请求,从而获取服务端是否允许该跨域的请求,以及是否需要携带身份凭证,最终决定客户端是否能否跨域访问资源,来保障网站的安全
那么什么样的情况下不会触发呢?MDN把这些归类为简单请求(不会触发CORS 预检请求 )
使用下列方法之一:
除了被用户代理自动设置的首部字段(例如 Connection,User-Agent)和在 Fetch 规范中定义为 禁用首部名称 的其他首部,允许人为设置的字段为 Fetch 规范定义的 对 CORS 安全的首部字段集合,该集合为:
Content-Type的值仅限于下列三者之一:(也就是html原生 form表单支持的数据类型)
text/plainmultipart/form-dataapplication/x-www-form-urlencoded
请求中的任意XMLHttpRequestUpload 对象均没有注册任何事件监听器;XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload
请求中没有使用 ReadableStream
Vue computed 和 watch的区别 ? computed 只要有依赖的项更新了,就会重新计算,内部还有做缓存,去做对比,如果值上一次计算的值,和更新的值没有发生变化,也不会更新到页面上(适合在模版里面使用,减少DOM更新)
watch 只要是被监听的值有变化,就会立刻执行 (适合做数据的监听的逻辑处理)
React class中哪些操作可以触发到 render ?
state更新
props更新
class的父组件更新,子组件也会更新
setState() 啥也不设置也会更新(只要调用了setState就会更新)
setState 是同步还是异步 ? 内部机制 ? 是异步的,执行setState 后不会立刻更新,而是把要更新的操作放入一个队列中
React 的事件操作 和 原生事件有什么区别 ? 合成事件 ? HOC 高阶组件是什么 ?作用是什么 ?
高阶组件函数接收一个组件 作为参数
高阶组件必须输出一个新的组件
更好的做代码分层复用,解决耦合等问题
React中不用第三方库,如何组件通信? (不用Mobx,Redux等)
Props + 事件触发 (父子组件通信)
使用 ref 获取到对应React实例 直接操作其他组件的方法,属性,进行通信
Provide ( Mobx 也是使用从根组件开始注入的方式,实现状态下发 )
Context (不好维护)
tips: 项目大起来还是用Redux 和 Mobx 库去管理比较好
Typescript type 和 interface 的区别 ? 说了一些,没说全,补充下
interface 可以描述class,type 不可以
interface 继承方式是 extends ,type 是用联合类型 &
interface 只能描述对象和 class ,type可以描述任意数据类型 (数据类型可以,class不行)
interface 不能使用 in 关键字进行遍历,type 可以使用 [key in Types] 进行对象的key约束
keyof 如何使用 ? webpack 说下webpack 的构建流程 ?
合并配置文件和参数,生成最终的配置文件 (如何有多个的话,例如:shell 脚本中的参数,Vue.config.js 等等)
从入口文件开始( entry字段),递归加载出所有依赖文件,生成依赖树
根据loader 配置的规则转化对应的文件
plugin …
代码提取,公共模块,代码分离,等等
生成文件写入 output 字段配置的文件夹
数据结构 树节点操作的优化 ? 堆栈是什么 ? 说下深度优先和广度遍历优先 ? whlie 循环遍历做树结构的优化 ? 笔试题 手写一个 防抖函数 当时直接写了思路,觉得在纸上写代码有点难受
function debounce (fn, delay ) { let timer = null ; return function (...args ) { if (timer) { clearTimeout (timer); } timer = setTimeout (() => { fn.call (this , ...args); timer = null ; }, delay); }; }
还有算法的笔试题 刚开始没看懂,后来他和解释了一波题意,然后马上就讲出思路来了,面试官表示比较满意,后来面试评价说我,反应灵活。。。😂,好吧
性能优化篇 说一下你知道的web性能指标 当时脑子抽了,说了一些,没太全,实际上就是问的,从浏览器输入URL到页面渲染这个过程中的一些指标啊。。。😂
网络层
重定向时间 (浏览器先检查本地是否有标记过,该URL 有被永久的重定向 httpCode 301)
DNS解析时间 (是域名的话,会递归的去解析拿到IP地址)
TCP 完成握手时间 (拿到IP后,开始于服务器建立TCP连接,中间会有三次握手过程)
HTTP请求响应时间 (三次握手成功后,HTTP开始发送请求,然后响应数据)
应用层
DOM解析时间 (获取到HTML后,浏览器开始解析)
Script 脚本加载时间( 如果DOM中包含了script,则会执行脚本)
onload 时间 (整个页面加载完成后,包括DOM 和 CSS ,Javascript 全局加载完成,比如JS阻塞,Image 的src 图片下载完成才触发onload事件,亲测)
pageload (页面完全加载是时间)
PNG,JPG,GIF,WEBP等图片格式有什么不一样,分别用于哪些场景?