彻底理解Node.js的Event Loop和非阻塞IO
介绍
Node.js是一个基于V8引擎的JavaScript运行时环境,它的特点是事件驱动、非阻塞I/O模型。事件驱动模型是基于事件循环机制的,而非阻塞I/O则是通过libuv库实现的,这两个特性是Node.js高效处理并发的关键所在。在本文中,我们将深入探讨这两个概念,并解释它们如何共同工作以提高Node.js应用程序的性能。
Node.js 特点
- 事件循环 Event Loop
- 非阻塞I/O (底层libuv实现)
适合处理高并发,低延迟的场景,比如网络应用、聊天室、实时通信等。
擅长做I/O密集型的应用
什么是Event Loop?
Event Loop是一个程序结构,用于等待和发送消息和事件。在Node.js中,它是运行时的核心部分,负责协调事件的顺序和执行回调。Node.js的Event Loop是单线程的,这意味着它一次只能执行一个事件或任务。
Node.js 的事件循环是一种非常高效的方式来处理 I/O 操作,它允许程序在等待 I/O 完成的同时执行其他任务,而不会阻塞整个进程。这使得 Node.js 非常适合构建高吞吐量、低延迟的网络应用程序。
单线程如何保证高并发?
JavaScript是单线程语言,这意味着它一次只能做一件事。 这对于浏览器中运行的代码通常没问题,因为用户界面(UI)交互通常不需要大量并行处理,但是,在服务器端,你可能需要同时处理成千上万的客户端请求。Node.js通过Event Loop实现了一个非阻塞的方式来处理这些请求,这样就可以在不增加更多线程的情况下高效地处理大量并发。
那么,事件循环和非阻塞IO都是是如何工作的呢?
Event Loop的工作原理
非阻塞IO原理
非阻塞IO是一种系统调用,允许程序在等待IO操作(如读取文件或网络通信)完成的同时,继续执行其他任务。这与传统的阻塞IO相对,阻塞IO会导致程序停止执行,直到IO操作完成。
在Node.js中,大多数库函数都是非阻塞的,这意味着它们会立即返回,然后在IO操作完成时通过回调函数通知程序。这种模式允许Node.js应用程序在处理大量IO密集型任务时保持高效率。
餐厅排队的例子就可以很好的解释阻塞IO和非阻塞IO的区别:
- 阻塞IO: 线下排队(需要一直等待,等到自己了才可以去就餐)
- 非阻塞IO: 线上取号(可以先拿号,等到号了再过来用餐,期间可以做其他的事情)
说完了非阻塞IO,接下来我们来看看Event Loop是如何工作的。
Event Loop的工作流程
Node.js的Event Loop遵循以下步骤:

- 执行同步代码:Node.js首先执行脚本的同步代码,例如变量声明和函数定义。
- 注册回调:当遇到异步操作时(例如文件读取或数据库查询),Node.js会注册一个回调函数,并继续执行Event Loop的下一个阶段。
- 事件队列:Node.js维护一个事件队列,其中包含由异步操作触发的事件和回调。
- 循环:Event Loop循环通过事件队列,并根据需要执行回调。这些回调被执行为了响应外部事件,例如HTTP请求到达或计时器到期。
Node.js的Event Loop包含几个阶段,包括:
- 定时器阶段:处理setTimeout和setInterval回调。
- IO回调阶段:处理几乎所有的IO相关的回调函数,例如读取文件、网络请求等。
- 闲置、准备阶段(idle prepare):这是一个内部阶段,一般不会由用户代码触发。
- 轮询阶段(Poll):检查新的IO事件,这个阶段,Node.js 将检查是否有新的 I/O 事件需要处理。如果有,它将执行对应的回调函数。。
- 检查阶段:setImmediate()回调在这个阶段执行。
- 关闭的回调阶段:例如socket.on(‘close’, …)这种回调。事件循环不断地在这些阶段之间切换,处理队列中的任务,直到队列为空。这种非阻塞的模型使 Node.js 能够处理大量并发连接而不陷入阻塞,因为它可以在等待 I/O 时执行其他任务。
Nodejs的Event Loop和 Javascript的Event Loop有什么区别?
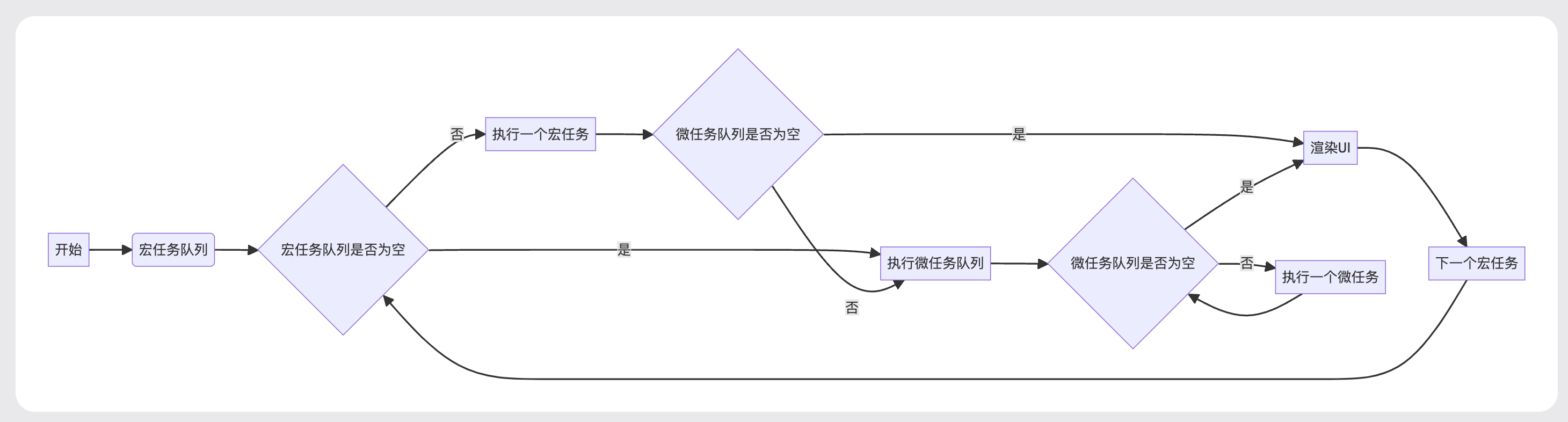
浏览器事件循环
- 浏览器首先会执行主线程上的代码(相当于宏任务),遇到微任务便将其推入微任务队列中,遇到宏任务便推入宏任务队列中
- 当主线程中的代码执行完后,会检查微任务队列是否为空,若不为空,则将微任务队列中的微任务推至执行栈中执行。在执行的该微任务的过程中,如果又遇到宏任务则将其推入宏任务队列,遇到微任务则推入微任务队列
当微任务队列执行完为空时,检查宏任务队列是否为空,如不为空,则将对头宏任务推入执行栈开始执行。该过程中,若遇到宏任务则将其推入宏任务队列,若遇到微任务,则推入微任务队列 - 每当执行完一个宏任务,不管宏任务队列中是否还存在宏任务,都必须去检查微任务队列中是否有微任务,若存在微任务,则开始执行微任务
这整一个操作一直重复,就是Javascript的事件循环,那它和Nodejs的事件循环有哪些区别呢?
区别:
- 在浏览器事件循环中,每执行完一个宏任务,便要检查并执行微任务队列;而node事件循环中则是在“上一阶段”执行完,“下一阶段”开始前执行微任务队列中的任务。也就是说,node中的微任务是在两个阶段之间执行的。如果是node10及其之前版本:要看第一个定时器执行完,第二个定时器是否在完成队列中。
- 在浏览器事件循环中,
process.nextTick()属于微任务,而且和其他微任务的优先级是一样的,不存在哪个微任务的优先级高就先执行谁。但是在node中,process.nextTick()的优先级要高于其他微任务,也就是说,在两个阶段之间执行微任务时,若存在process.nextTick(),则先执行它,然后再执行其他微任务。
优化技巧和注意事项
- 尽量避免在事件循环中执行长时间运行的同步操作,以免阻塞其他任务的执行。
- 使用async/await和Promises来更好地管理异步流程,使代码更易于理解和维护。
- 谨慎使用setImmediate(),只在必要的情况下使用,以避免破坏事件循环的正常执行流程。
- 传输大文件时使用stream进行管道传输,避免一次性读取整个文件到内存中。关于stream的操作,可以参考Node.js Stream stream也有内部的优化策略 Backpressure 背压处理。
背压处理
背压处理是一种流控制策略,用于处理生产者和消费者之间的速度不匹配问题。在Node.js中,stream模块提供了一种内置的背压处理机制,可以帮助应用程序更好地处理大量数据的传输。
在Node.js中,背压(Backpressure)是指在流(Stream)处理中,生产者(数据的写入方)的数据生成速度超过消费者(数据的读取方)处理速度的情况。当这种情况发生时,如果不加以控制,就可能导致内存的过度使用,乃至应用程序的崩溃。背压处理机制就是用来防止这种情况的发生,确保流的稳定性和效率。
在Node.js中,流是基于事件的,可以使用stream模块来处理数据。流分为可读流(Readable),可写流(Writable),双工流(Duplex)和转换流(Transform),每种流都有特定的背压处理机制。
以下是Node.js中处理背压的一些机制:
可读流(Readable):
可读流通过pause()和resume()方法提供了手动的流量控制(Flow Control)。
当消费者还在处理数据时,它可以调用pause()方法来暂停流的数据读取。
一旦消费者准备好接收更多数据,可以调用resume()方法来恢复流的数据读取。
在新的流(Streams API的v2以后)中,可读流会在内部自动管理背压,即消费者通过.read()方法读取数据时,流会自动管理背压。
可写流(Writable):
可写流通过write()方法返回的布尔值提供了背压的信号。
当write()返回false时,这是一个信号,告诉生产者应该停止写入数据,直到drain事件被触发。
一旦内部缓冲区的数据被消费者(可写流)处理完毕,就会触发drain事件,生产者可以监听这个事件来恢复数据写入。pipe()方法:
pipe()方法是一个简化流量控制的工具,它自动处理背压,将一个可读流的数据导入到一个可写流。
它监听可读流的data事件来获取数据,并使用可写流的write()方法来写入数据。
如果write()返回false,pipe()会自动暂停可读流的数据读取,等待可写流的drain事件再次恢复读取。
通过这些机制,Node.js在流处理中维持了数据的平衡,防止了内存的浪费,确保了应用程序的稳定性和性能。开发者需要了解这些流控制的概念,并在实现流处理逻辑时恰当地使用它们,以避免背压问题。